圈复杂度
过去我知道有圈复杂度这个概念,它代表了代码的复杂程度。但是却没有了解过它是怎么算出来的,哪些代码会影响它的结果。 今天我们就来看一下,圈复杂度这个概念。
什么是圈复杂度
圈复杂度这个概念在 1976 年就已经被提出来了,比很多编程语言还要古老。 它的英文名是 Cyclomatic complexity,中文是圈复杂度、循环复杂度或者条件复杂度。 显然圈复杂度并不是一个好的翻译,因为第一次看到的时候,其实不知道它是个什么东西。但是另外两个名字也只能表示它的部分内容。
圈复杂度被用来判断程序的复杂程度,圈复杂度越高,则代表程序越复杂。 它的数值代表的是程序的线性独立路径的数量。
线性独立路径,又被称作线性无关路径,是一条至少包含一条在其他任何线性独立路径中从未有过的边的路径。
如何计算圈复杂度
单结束点
对于单结束点的程序,圈复杂度的计算公式很简单,我们需要先画出程序的控制流图,用 M 代表圈复杂度:
M = E - N + 2P上面的:
E:图中的边的数量
N:图中的节点数量
P:图中
connected component的数量
connected component是来自图论的概念,叫做元件,它是一个无向子图,上面的所有节点都不能到达子图以外的节点。 在程序设计的上下文里,这个值永远是 1。
我们可以看一下这个例子:
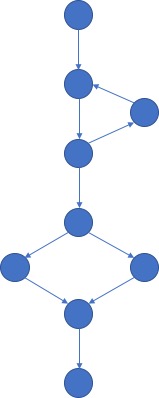
在这个图中,我们有 10 条边、9 个节点、1 个元件,所以 M = 10 - 9 + 2 = 3。
对于程序而言,因为只有一个进入点,所以上面的公式可以再做一步简化:
M = π + 1其中,π 代表程序中的决策点。
多结束点
对于多个结束点(比如多个 return 语句)的程序,上面的公式就不太适用了,而需要一个新的公式:
M = π - s + 2其中 s 代表结束点的数量。我们可以发现这个公式同样适用于单结束点的程序。
影响圈复杂度的因素
既然知道了计算圈复杂度的公式,那么我们就知道了影响它的因素:决策点和结束点。
对应到代码里,结束点就是 return 语句和 throw exception。
而决策点就很多了,不仅包括 if、case、for 等语句,三元表达式和 catch 语句同样也是决策点。
这也是为什么说循环复杂度和条件复杂度这两个翻译不够好的原因,因为决策点包含了循环和条件控制这两个内容。
想要降低圈复杂度,我们可以选择增加 return 语句,比如提前 return 或者 throw exception。 我们也可以选择减少 if 等语句的使用,通过抽方法、合并条件等重构手段达到这个目的。
圈复杂度与代码质量
圈复杂度与代码质量息息相关。
因为越复杂的代码,越难以维护,一点小小的改动就可能造成程序运行失败。 所以在一些代码扫描工具中,比如 sonarqube,就要求方法的圈复杂度不能高于 10。
另外,越复杂的代码,意味着越难以测试。因为我们需要让测试覆盖到尽可能多的情况,圈复杂度越高,意味着需要覆盖的情况越多,测试也就越难写。 这可能就导致这段代码没有被完整的覆盖到,再加上较高的圈复杂度导致代码阅读的困难,就难以保证对它的修改不会破坏掉它的功能。
所以,为了增加代码质量,我们应该尽可能的减少圈复杂度。
总结
我们了解了圈复杂度代表的是程序的控制流图的线性独立路径的数量,代表了程序的复杂程度。增加结束点和减少决策点都能减少圈复杂度。
思考
尽管程序员可以修改代码降低各个程序函数的圈复杂度,但是整个程序的圈复杂度却不会改变,因为这是由业务决定的,而不是可以通过修改代码而改变的。 而且在程序设计中引用圈复杂度,本来就是为了能在函数级别降低复杂度,而不是为了降低业务复杂度(本来也做不到)。 所以不必纠结“方法的复杂度是下降了,但是整体的复杂度却没有”这种事情。