以领域为核心的架构们如何指导我们写代码
刚开始工作的时候就接触到 DDD,当时就被它规定的代码模式所吸引。几年下来,接触到不同的代码组织模式,更是深深的感受到一个“良好”的代码架构是多么重要。
Note | “良好”的代码架构,应该让人在添加新代码时不繁琐和迷茫,应该让人在修改代码时不容易遗漏,应该让人能够准确的找到某个业务对应的代码。 |
以这样的眼光来看,传统的分层架构就难以做到这几点,而一些以领域为核心的架构则相对容易一些。
传统的分层架构如何组织代码
我们先来看看分层架构是如何组织代码的
分层架构有哪几层
在传统的分层架构中,代码被分成了 API、Service、Repository 这样三层,每一层处理不同的事情。
API 层
API 层处理和 HTTP 协议交互的部分。如果使用 Spring 框架,那么也会把这一层叫做 Controller 层。这仅仅是因为 Spring 中使用 @Controller 作为注解而得名。
Repository 层
这一层主要负责和存储技术打交道。存储技术往往就是数据库。这一层也有很多的框架可以利用,比如 Hibernate、JOOQ、MyBatis。
Service 层
Service 层处理和业务相关的事情。虽然名义上是这样说,但实际上所有我们认为不应该交给 API 层和 Repository 层的代码,都会被放到 Service 层。这样的结果就是 Service 层中的代码逐渐变大,最终没人能够讲清楚一个 Service 层里的方法到底做了多少事情。
因为所有的代码都在 Service 层,所以 Service 层的代码就会变得冗长,很容易出现一个方法职责过多的问题。但是单一职责原则又会在程序员的脑海中回响,逼迫程序员做重构。而这时的重构往往就是抽方法。然后一个类中的方法就会越来越多,并且在一个类中处理了不同的事情。于是单一职责原则又开始回响,程序员又不得不再次重构。这时,往往就会出现“没有什么问题不是多加一层不能解决的”。于是在 Service 层中就出现和各种各样的层,当我们阅读代码的时候往往就会迷失在其中,逐渐搞不清楚自己要添加的代码应该放在哪里。
层与层之间的依赖关系
在分层架构中,层级之间的依赖关系是向下的,如下图所示:

我们可以看到,在这样的代码组织方式中,依赖的最终指向是数据库。也就是说,数据库成为了系统的核心。但是我们开发一个系统,应该是围绕着要解决的问题来编写代码,数据库只是一个存储数据的地方而已。在这样的组织方式中,代码围绕这数据库而设计,当数据库发生变化时,代码就会发生变化。但是这些代码并没有把业务代码与数据库代码解耦,所以修改起来就像是在整理从口袋里拿出来的耳机线一样难受。
以领域为核心的架构们如何组织代码
面对传统的分层架构的问题,人们提出了一些新的架构模式。这些模式中,有三种在今天被大家所熟知。它们分别是洋葱架构、六边形架构(又叫做端口-适配器架构)、整洁架构。
三种以领域为核心的架构
接下来,我们先来看看这三种架构是什么。
Onion Architecture
洋葱架构的原文可以在原作者的博客中找到。作者一共用了四篇文章来解释洋葱架构是什么。
我们可以简单的总结一下洋葱架构的特点:
以 Object Model 为核心, Object Model 不依赖 Object Model 以外的任何概念
围绕着 Object Model 的是 Object Service(或者叫做 Repository),提供 Object Model 的查询和保存
围绕着 Object Service 的是 Application Service,负责对外提供接口,也会包含一些业务逻辑
洋葱架构要求了代码的依赖关系,如下图:

图中,蓝色箭头代表了依赖方向,橙色部分圈出的是应用的核心。而数据库之类的代码,则放到了 infrastructure 里面。
Port Adapter Architecture
我在之前的文章中介绍过六边形架构。它的特点是把与外部技术实现相关的代码隔离到适配器中,在应用核心代码中声明端口,这些适配器去实现端口,从而把与核心业务无关的技术实现从核心代码中解耦出来。
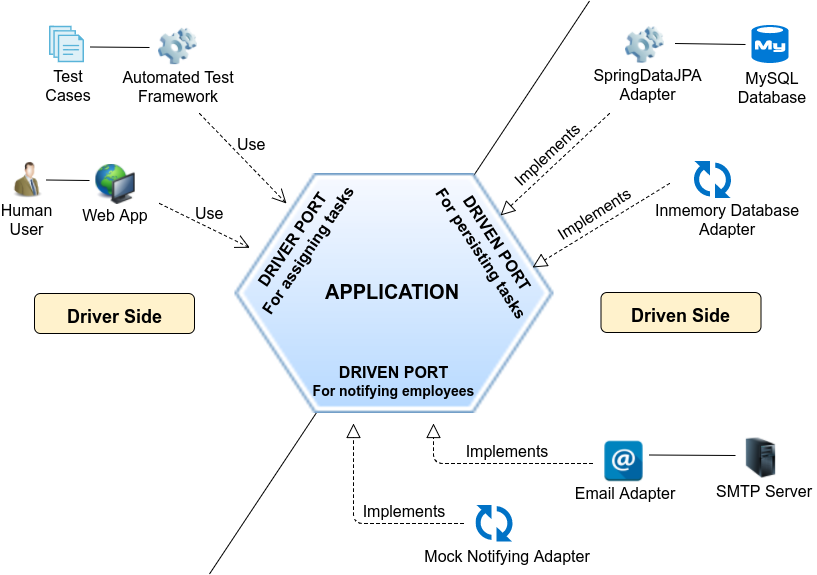
六边形架构与洋葱架构的相同点是,它们都把与核心业务无关的技术实现代码从应用的核心代码中解耦出来。
它们的不同点是,六边形架构只约束了如何把这些技术实现解耦出来,而没有约束如何组织核心业务代码。洋葱架构则对此做了一些约束,定义了 Application Service、Object Service 和 Object Model,并明确了它们之间的依赖关系。
Clean Arch
整洁架构是 Uncle Bob 总结了多种架构模式后提出的一种架构模式。

和洋葱架构一样,我们可以看到多个同心圆和指向内部的箭头。它们也代表了代码的核心程度和依赖关系。
在洋葱架构中:
Entities 是业务实体,它们可以包含数据和行为
Use Cases 负责组织实体间的调用
Interface Adapters 负责提供 Restful API、CLI、数据库访问等与业务核心不相关的技术代码
Framework & Drivers 负责提供第三方的框架、库等不需要自己动手编写的代码
因为整洁架构是从前面两个以及其他架构设计中总结出来的,所以我们能发现它有它们的影子。与前两个架构一样,它们都强调要把和核心业务无关的代码隔离到应用核心代码之外。与前两个不一样的地方是核心代码的组织方式,洋葱架构有 Application Service、Object Service 和 Object Model,并且没有强调 Object Model 是否可以有行为;六边形架构没有对此做约束;整洁架构有 Use Cases 和 Entities,并且明确表示 Entities 是可以有自己的行为的。
三种架构的前置条件
就像刚才说的,这三种架构都有一个共同特点,就是隔离与核心业务无关的技术代码。要实现这一点,就需要使用到依赖注入原则。
因为在这三种架构中,都是在核心代码里声明出要调用的接口,然后再在外部实现这个接口。实现代码中就出现了和具体技术相关的代码,比如 SQL 或 NoSql,而在接口声明中却对这些技术一无所知。这意味着随时可以替换掉实现代码,而不需要对核心业务代码做任何修改。
Note | 这里说声明的是接口,其实已经与一些语言绑定了。实际上,只要能够支持依赖注入原则,这里并不关心声明的是接口还是什么东西,只要足够抽象,不包含实现细节就好。 |
三种架构与 DDD
我时常会把 DDD 与这些架构模式放到一起思考。因为 DDD 实际上没有说到底应该如何写代码,这也导致了 DDD 的代码形式千变万化。实际上,我认为它们的关注点其实是不一样的。
三种架构的关注点
我认为这三种架构的关注点在于把技术细节隔离到业务核心代码之外,它们的共同点也在于此。正如标题说的一样,它们都是以领域为核心的的架构。至于领域里面如何组织,它们其实有不同的意见。所以我会认为它们更多的可取之处在于把与核心业务无关的代码隔离出去这种思想。
DDD 的关注点
领域内部的代码如何组织,实际上是 DDD 擅长的事情。在 DDD 中,Eric 介绍的模型驱动设计就是一种组织领域内代码的方式。
在模型驱动设计中,根据业务来设计模型,就会设计出 Entity、Value Object、Domain Service 等内容。这些构造块就可以直接对应到业务代码中。
所以,在我看来,一个合理的架构应该是这样的:

图中的蓝色箭头表示依赖的方向,橙色的圈表示业务代码的边界。
和前面的三种架构相比,我只是优化了一下组织业务代码的方式,提倡使用 DDD 来组织业务代码。而如何隔离具体技术实现的代码,仍然是使用依赖注入原则。
如何实践这些架构
前面提到的三种架构,都在强调依赖关系:业务代码应该只关注业务,不和数据库之类与业务无关的代码打交道,它们不应该依赖于外部代码。
所以,要实践这些架构,就需要保证代码的依赖关系。
保证依赖关系、
保证依赖关系有多种方式,这里介绍的是我想到的几种方式。
通过 Code Review 来审阅依赖关系
通过每日的 Code Review 来关注依赖关系,从而保证没有错误依赖。这是一种人工保证的方式,实践起来非常困难,容易出错。很可能因为关注依赖关系的人没有参与某一次 Code Review 导致依赖关系被破坏。而且有的团队不一定能够实践每日 Code Review。
不过在没有找到合适的技术解决依赖关系时,这也许是一种临时方案。
通过拆分 project 来保证依赖关系
Gradle 和 Maven 这种工具是支持拆分 subproeject 的,我们可以利用这个特性来保证依赖关系。
我们可以把业务核心代码放到名为 core 的 project 中;把提供 RESTful API 的代码放到名为 rest 的 project 中;把提供 MySQL 支持的代码放到名为 mysql 的 project 中。这样,我们就可以通过组合 rest 和 mysql 这两个 project 得到一个可部署的 project。
当我们想提供一个 CLI 版本的应用时,就可以添加一个名为 cli 的 project,再与 mysql 这个 project 组合成一个新的可发布的 project。
当我们想换掉 MySQL,提供 PostgreSQL 的支持时,就可以添加一个名为 postgresql 的 project,再组合成一个新的可部署的 project。

这种方式的优势是,每当业务代码更改时,可以同时发布所有发行版。并且为核心代码提供新的支持,不需要破坏原有的任何代码。
当然这种方式需要更高的技术成本,比如单独的 CI、团队成员对 subproject 的学习等等。
可视化依赖关系
可视化代码中目前的依赖关系,可以帮助我们一眼了解项目目前的代码关系,从而了解代码关系是否符合设计,同时也能发现潜在的依赖问题。
不过这方面我暂时没有找到现成的工具,也许是一个可以尝试写代码实现的内容。
总结
现有的几种架构模式都在讲把业务无关的技术实现代码从业务代码中解耦出来,通过严格的依赖关系要求,保证业务代码处于核心地位。
业务代码我们则可以使用考虑 DDD 中的模型驱动设计来设计对象的命名、职责、关系。
利用单元测试或者构建工具的 subproject 这样的功能,我们可以通过技术手段保证依赖关系,从而保证业务代码的核心地位。
有了这样的依赖关系,当我们添加、修改代码的时候,就能明确的知道应该把哪些代码写到哪些地方,而不会像在分层架构中那样迷茫,最后变成“多加一层就能解决”。